

Go-Champion ohne menschliches Zutun
AlphaGo hat sich heuer auch mit einem glatten 3:0-Sieg gegen den vermutlich weltbesten Go-Spieler Ke Jie durchgesetzt. An diesen Erfolgen wurde ersichtlich, wie weit die Entwicklung sogenannter Künstlicher Intelligenz (KI) bereits fortgeschritten ist. Das System stammt von der britischen Firma DeepMind, die vor mehr als drei Jahren vom US-Konzern Google übernommen wurde.
Die Studie
„Mastering the game of Go without human knowledge“, Nature, 18.10.2017
Besonders überraschend waren die Fähigkeiten von AlphaGo, weil das rund 3.000 Jahre alte asiatisch Spiel spezielle Anforderungen stellt, die bisher eher dem menschlichen Geist exklusiv zugebilligt wurden. Angesichts nahezu unbegrenzter Möglichkeiten für Züge, ist nämlich viel Intuition, kreatives Denken und Lernfähigkeit gefragt.
Am Problem lernen
Während AlphaGo seinen virtuellen Geist noch am Studium von Millionen Zügen von menschlichen Top-Spielern über Monate hinweg gestärkt hatte, gingen die Wissenschaftler um David Silver von DeepMind in London nun andere Wege: Im Zentrum der neuen Generation stand demnach der Gedanke, ein System zu bauen, welches das Spiel ohne Anschauungsmaterial von der Pike auf selbst erlernt und auf sich alleine gestellt weiterentwickelt - also „komplett ohne menschliche Intervention funktioniert“, erklärt Silver.
Die Fähigkeit ein System dazu zu bringen, etwas annähernd von Null auf zu erlernen, sei vor allem dann wichtig, wenn es darum geht, eine Form von KI zu entwickeln, die sich selbstständig auf für sie neue Aufgaben jeglicher Art einstellt. Am Ende strebe man die Entwicklung eines Algorithmus an, der potenziell auf jedes Problem angesetzt werden kann, so der Forscher, in dessen Team der 25-jährige Niederösterreicher Julian Schrittwieser mitgearbeitet hat. Der Softwareentwickler ist seit 2012 bei Google. Sein Engagement entwickelte sich direkt aus einem Praktikum, das er noch im Rahmen seines Studiums an der Technischen Universität (TU) Wien absolviert hat, wie er gegenüber der APA erklärt.
Minimale Startinformation
Nach der Übernahme von DeepMind durch Google wurde Schrittwieser durch einen Vortrag von Ko-Firmengründer Demis Hassabis auf AlphaGo aufmerksam. „Das hat mich dann so interessiert, dass ich zu DeepMind gewechselt bin“, sagt Schrittwieser. Seine Expertise sowohl im Soft- und Hardware-Bereich als auch beim maschinellen Lernen habe auch zu der aktuellen Arbeit beigetragen, bei der Schrittwieser als einer der Hauptautoren fungiert.
Lerntempo (Animierte Grafik von DeepMind)
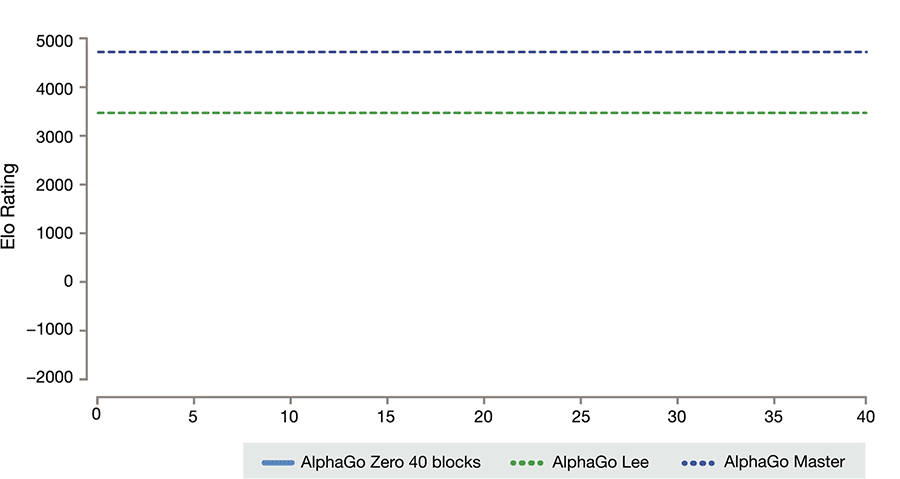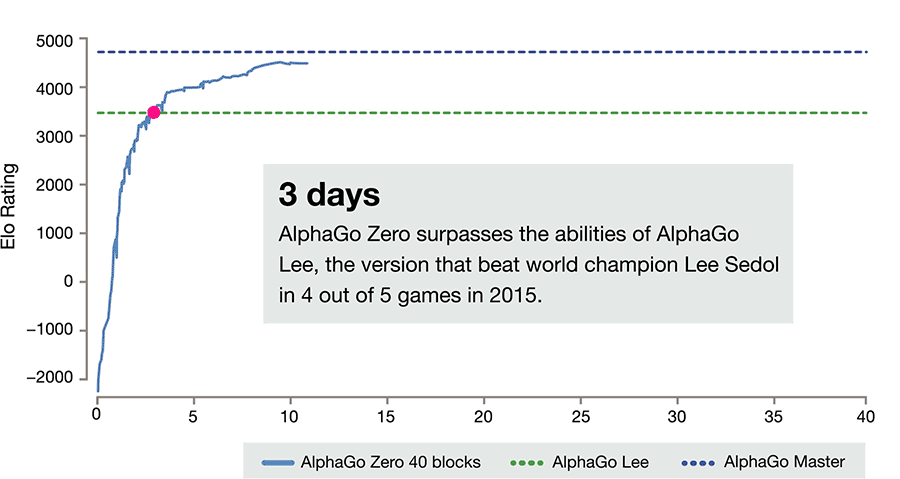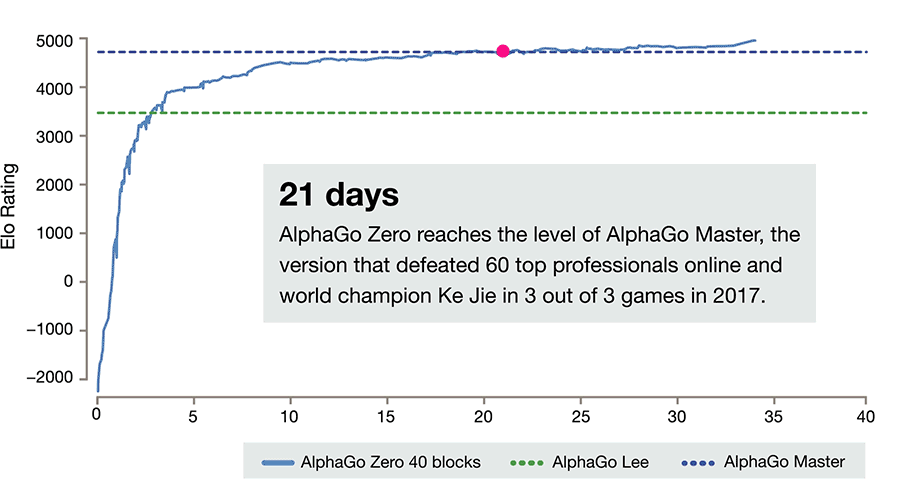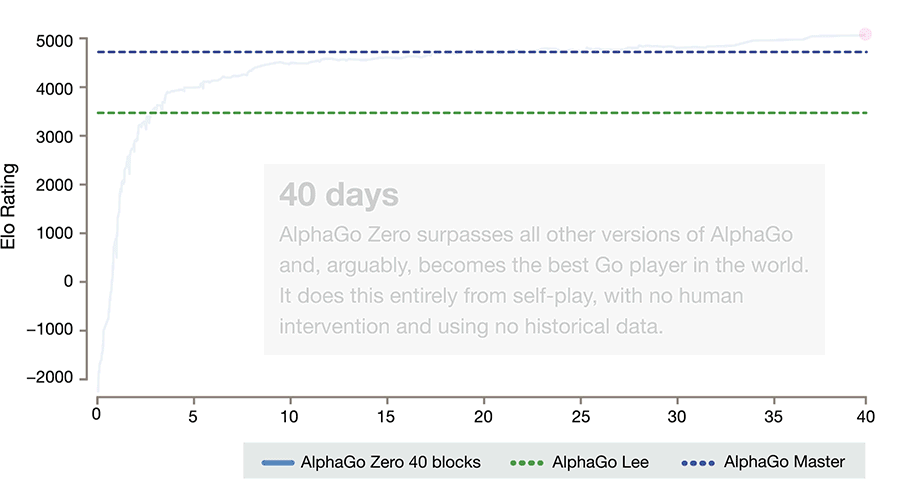
Das von ihm mitentwickelte neue System begann mit nur minimaler Startinformation über die Regeln und Beschaffenheit des Spiels gegen sich selbst zu spielen. Grundlage von AlphaGo Zero ist ein künstliches neuronales Netzwerk, das darauf abzielt, die Auswahl der nächsten Züge des Programms und den Gewinner der jeweils gespielten Partien vorherzusagen. Für gewonnene Spiele wurde es durch ein Punktesystem belohnt. Dadurch „lernte“ AlphaGo Zero mit jedem Spiel dazu.
Nach wenigen Tagen - allerdings immerhin nach fast fünf Millionen Partien gegen sich selbst - schlug das Programm alle seine Vorgänger. Jenes System, das mit den Siegen gegen die Spitzenspieler aufhorchen ließ, ging mit einem klaren 100:0 unter. Dafür brauchte es weit weniger Rechenressourcen als AlphaGo, heißt es seitens DeepMind.
Münchhausen Trick
Nicht nur habe der Algorithmus sozusagen all das in kurzer Zeit herausgefunden, was Menschen in tausenden Jahren über das Spiel gelernt haben, er habe auch völlig neue Herangehensweisen entwickelt. „Ich denke, ich kann für das Team sprechen, dass wir alle angenehm überrascht darüber sind, wie weit sich das System entwickelt hat“, so Silver. Für Schrittwieser sind die neuen Erkenntnisse ein Schritt in Richtung des Verständnisses des großen Mysteriums der menschlichen Intelligenz, von deren Verständnis man natürlich noch weit entfernt sei.
Von Seiten unbeteiligter Experten gibt es Anerkennung für die Arbeit des DeepMind-Teams. „Wieder einmal ist den Kollegen bei Deepmind ein großartiger Coup gelungen, denn sie konnten zeigen, dass ein intelligentes Go-Programm, das gegen sich selbst spielt, lernt, noch besser zu werden als wenn es aus Spielen von Menschen lernt. Das klingt, als ob man Wissen aus dem Nichts schöpfen könnte, sozusagen ein Münchhausen Trick der Künstlichen Intelligenz", meint etwa Klaus-Robert Müller von der Technischen Universität Berlin.
Andere Kollegen steigen hingegen auf die Euphoriebremse: Die Wissenschaftler hätten in der Arbeit „selbst ja keine fundamentalen algorithmischen Neuerungen vorstellt, sondern hauptsächlich existierende Verfahren clever kombiniert“, erklärt Marcus Liwicki von der Technische Universität Kaiserslautern. Die Anwendbarkeit des Ansatzes in anderen Bereichen wäre außerdem eher eingeschränkt, da das System eben Millionen von Spielen durchführen muss, bei denen Erfolg eindeutig definiert ist, um derart gut zu werden. „Das ist in vielen praktischen Problemen jedoch nicht der Fall“, so Liwicki.
science.ORF.at/APA